听闻蜗牛矿机翻车已久,最近装了100M下行25M上行的宽带后终于决定买一个当NAS试试。
所需的所有脚本(除 Ceph 搭建外)都可以在 https://github.com/ihciah/NAS-tools 上找到。
基本信息
宽带
款单图便宜装了联通的 500 块/年的 100M 光纤,相比电信便宜了一半还多。
宽带装完发现是光猫拨号,于是打10010要桥接+公网IP。客服表示我不懂啥是桥接但是我可以帮你交个公网IP的申请。10 分钟后重启光猫发现公网IP已经有了,但是改不了桥接也配不了端口映射我要这公网IP何用!
继续骚扰 10010 ,很快小哥上门来折腾,一开始没有搞定。本想用 TTL 大法强行拿光猫管理员账号,小哥直接告诉我,密码就是 CUAdmin(ZXHN F477V2)。后来直接换成旧款光猫,小哥一番折腾后搞定桥接。
硬件
路由器也是最近新购买的,考虑到性价比又手贱选了小米。¥169 = 小米 4A 千兆版,看说明倒是一点不坑,全千兆还有 IPv6 支持,结果一堵墙 5G 信号就掉一格。路由器附近 50MB/s ,隔墙距离 3 米左右就掉到 20MB/s 。买的上一个小米路由器(3Pro)多少还开放所谓的开发版(就是给 root 权限的劣化版Open-WRT),还给了 build 工具让我折腾个小飞机,这个连权限都不给,而且 IPv6 也不支持。 继续跟我读:垃圾小米!
UPDATE-2019-05-25:
小米路由器 4A 千兆版断流问题严重!已退货,换了 RT-ACRH17。
再买小米我是狗!
矿机感觉挺棒的。¥338 = 蜗牛矿渣一台,双千兆 + 4 SATA + 4 GB + 16G SSD,电源是祖玛的感觉素质海星, SSD 型号没记住,似乎是个国产垃圾货,但是我对 SSD 没有很高的要求。¥29买了一个 12cm 风扇换上,基本零噪音。性价比一流啊!(甚至想再买一台
| 路由器和光猫(树莓派误入 | 蜗牛矿渣 |
|---|---|
 |
 |
软件
NAS 有一些热门的选择。白群晖价格贵但是比较稳定,送穿透;黑群晖性价比高但是比较折腾,得不到最新的更新;还有一些专门的 NAS 系统如 FreeNAS ,但是这东西至少要求 8GB 内存,这定位就很尴尬。
查了下群晖的 CVE 列表,发现这家的产品不光用开源轮子,自己也造轮子,还有的是 PHP 轮子。联想到以前差点就用了的 MT 工具箱这种小作坊出品的漏洞爆炸的轮子,我还是自己折腾吧。
系统出于简便考虑装了 Debian 9,最简安装,无桌面环境。
存储系统没有做软 RAID ,用了 Ceph:一来因为 RAID5 也并不能高概率恢复文件,二来我不同的数据有不同的副本需求,第三就是看未来需求有可能需要搞多机。Ceph 在这方面就好很多,单节点也可以尽可能将数据分散在不同 OSD 上。
(其实用 Ceph 只是想玩一玩~如果是单机,不图折腾可以直接 btrfs,也能多副本和自动恢复。)
如果有多机那么通过 k8s 部署 rook 也是不错的选择;但是这矿渣性能比较渣,服务少跑一个是一个,就不搞 k8s 了。
系统搭建
Ceph
首先使用
apt安装ceph-deploy。1
2
3wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
echo deb http://download.ceph.com/debian-luminous/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
sudo apt-get update && sudo apt-get install ceph-deploy安装必要的组件。
1
2sudo apt-get install ntp
sudo apt-get install openssh-server配置用户,注意用户名不能为
ceph。之后为其配置免密码sudo并配置私钥登陆。主机名也需要修改为节点名,并在
/etc/hosts中建立对应解析。mkdir xcluster && cd xcluster ceph-deploy new nodeosd pool default size = 2 mon allow pool delete = true public_addr = your-ip osd crush chooseleaf type = 01
2
3
之后修改 `ceph.conf`,添加:1
2
3
4
5
6
7
8
9
10
11
12
13
其中 `osd crush chooseleaf type = 0` 必须要写。因为本系统只有单节点,`ceph` 默认将数据分散在不同的机器上,而本例中只需要不同 `OSD` 即可。以及每个 `OSD` 大概需要耗费 `1GB` 的内存,鉴于比较穷不想加内存,这里使用了额外的 `OSD` 配置项限制了它的内存占用,反正性能已经看淡了,毕竟用的是5年前的垃圾硬盘(J1900 其实也挺垃圾的)。
若集群在没有该配置的情况下创建,则直接影响到 `CRUSH`。后续即便是修改配置并推给节点(`ceph-deploy --overwrite-conf config push node`)也不会work。这时必须修改 `CRUSH` 。
```shell
ceph osd getcrushmap -o {compiled-crushmap-filename}
crushtool -d {compiled-crushmap-filename} -o {decompiled-crushmap-filename}
Change "step chooseleaf firstn 0 type host" to "step choose firstn 0 type osd"
crushtool -c {decompiled-crush-map-filename} -o {compiled-crush-map-filename}
ceph osd setcrushmap -i {compiled-crushmap-filename}安装
ceph至所有节点。1
2ceph-deploy install --release luminous node
ceph-deploy mon create-initial这里也踩了坑。按官方文档是不加
--release的,结果默认装错了版本。ceph-deploy disk list node(列出node上的磁盘)ceph-deploy disk zap node1 /dev/sdb(抹掉sdb的所有数据,若执行出错需要手动fdisk清空分区后重试)ceph-deploy osd create --data /dev/sdb node(创建OSD)这里也踩过一个坑,就是在VPS上进行调试时,删除过一次集群并重装,结果提示硬盘被占用。除了需要检查硬盘是否被挂载,还需要检查
/dev/mapper。如果设备被map,则需要dmsetup remove掉。最后可以将本机创建为管理机:
ceph-deploy admin node。
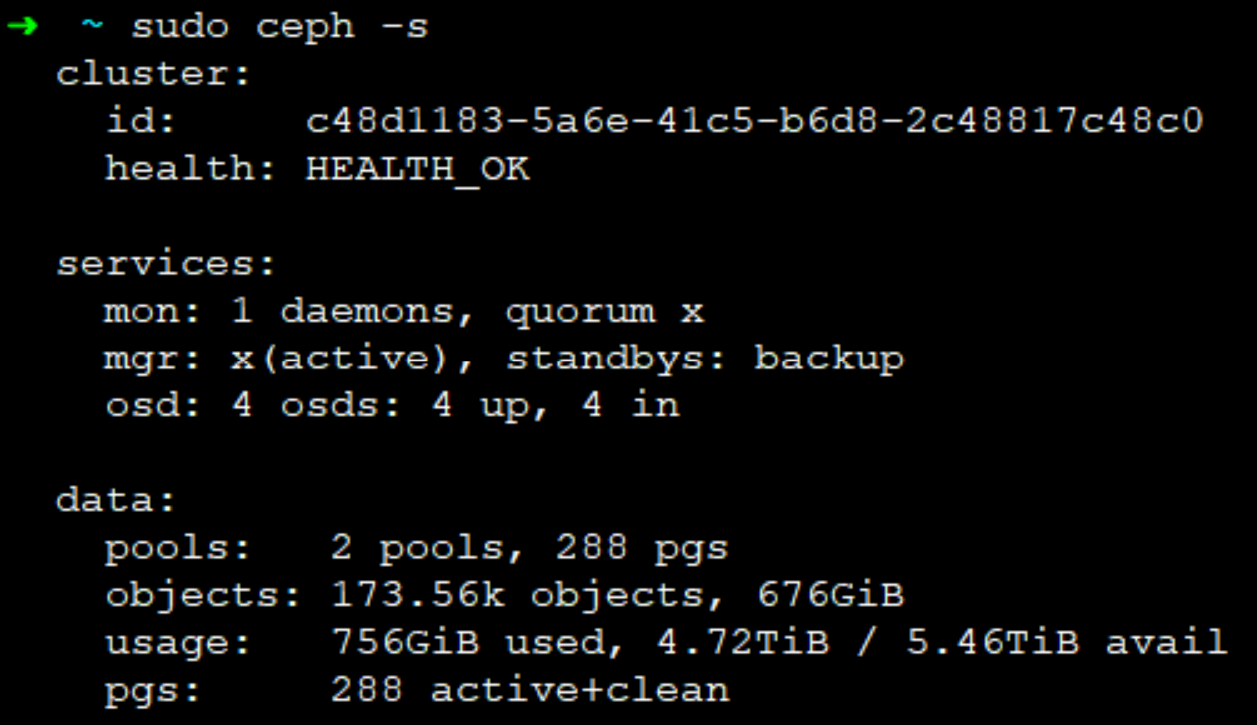
到这里 Ceph 安装基本完成。
单节点的 Ceph 其实问题挺多,比如一个常见的问题就是关不了机器。
在关机时系统先关闭了 Ceph 的服务,然后在卸载挂载的目录时会导致无法回写而卡住。这个问题调整优先级即可解决,更简单的办法是改 reboot.target 和 poweroff.target,指定在关闭服务前卸载目录:
ExecStop=/bin/umount /mnt/common-blk /mnt/rep-blk
UPDATE(9/21/2019): 关于内存消耗:
Ceph 吃内存吃的厉害,为了不爆掉系统的其他服务,有必要对其限制一下内存使用。
首先应用了 Ceph 自己的一些参数:
1 | bluestore_cache_size = 357913941 |
然并卵,还是会爆我内存。然后我们可以尝试通过系统对其进行限制,cgroups 或者 ulimit 都可以实现。
简单起见,我直接设置了 /etc/security/limits.conf, 新增了对 ceph-deploy 用户的限制:
ceph hard as 4096000,目前运行良好。
并且 ceph 运行时也会占用大量的内存 cache,这部分是不受 ulimit 限制的,如果占满就会去占用 swap。
为了降低对 ssd 的写入,我关掉了 swap 分区,并通过配置 sysctl.conf 采用更积极的 cache 清理策略。
CephFS
(本节测试过但由于性能不佳并未部署使用)
CephFS是一个基于Ceph的文件系统,其中文件系统元信息存储于MDS节点。
1 | ceph-deploy mds create node |
然后创建Pool并且使用Pool创建CephFS。
1 | sudo ceph osd pool create normal 256 |
挂载CephFS这里直接使用内核驱动。
1 | sudo mount -t ceph node:6789:/ /mnt/mycephfs -o name=admin,secret=aa |
RBD
比起用CephFS管理文件元信息和数据,更简单的是搞一个块设备,并自行创建文件系统,在随机读小文件上性能要优于CephFS。
1 | rbd create --size 1024 normal/testblock |
映射RBD:
1 | sudo rbd map rbd/myimage --id admin --keyring path/to/keyring |
遇到提示错误可以 dmesg | tail 看报错,不支持的 feature 可以关掉。
1 | sudo rbd feature disable normal/testblk object-map, fast-diff, deep-flatten |
确定kernel的支持后可以修改 ceph.conf: rbd_default_features = n
自动映射可以修改 /etc/ceph/rbdmap,添加:
1 | foopool/bar1 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring |
并 systemctl enable rbdmap.service。
若要系统自动挂载,可以在 /etc/fstab 中添加:
1 | /dev/rbd/foopool/bar1 /mnt/bar1 xfs noauto 0 0 |
另外,可以添加 discard 选项,否则删除文件后 Ceph 的可用空间不会增加,但这样做也会一定程度上影响性能。
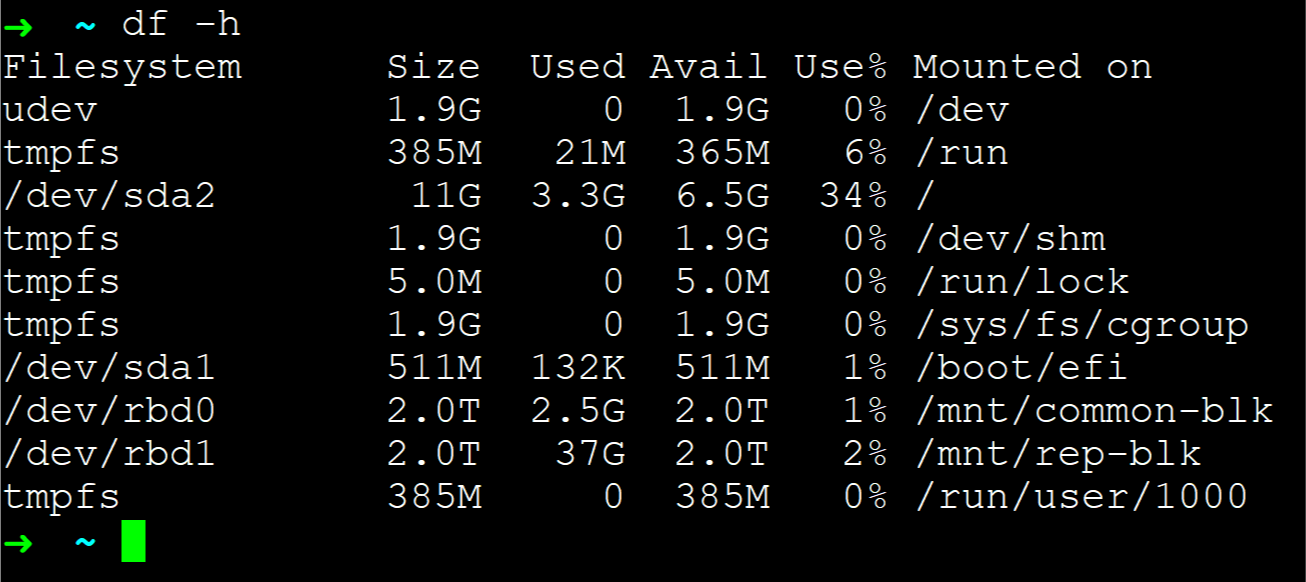
RBD 可以轻松扩容,而且这个容量只是代指其容量上限,并不影响实际空间占用。但是有一点比较坑,就是扩容的时候一定要注意单位!我搞错了单位,多了 6 个 0,结果 shrink 巨慢,参考这个,最后决定不搞了== RBD 大就大吧,这个限制不要了,然后扩容文件系统的时候限制一下。XFS 可以使用 -D 参数指定 block 个数:
1 | sudo xfs_growfs -D 1048576000 /dev/rbd/common/common-blk |
Samba
1 | sudo apt install samba |
查看所有用户: pdbedit -L -v
之后修改 /etc/samba/smb.conf,注释掉不需要的目录并添加:
1 | [personal-common] |
本例中每个用户有3个目录,分别对应个人的普通数据、多副本数据和所有用户共享的数据。
部署完成后发现联通屏蔽了 445 端口,打出GG。
既然要有效利用上行带宽,那就只能直连。所以一个很直接的想法就是路由器上用别的端口转发一下,用户终端再转回 445。
我的笔记本运行了文件共享服务,这东西默认监听 0.0.0.0:445 ,所以比较简单的办法就是直接关掉这东西。
1 | $netBTParametersPath = "HKLM:\SYSTEM\CurrentControlSet\Services\NetBT\Parameters" |
执行这段 Powershell 后重启即可。本来不想关掉的,折腾了一下 TAP-Windows ,想直接创建一个虚拟网卡,然后 TUN 模式过滤一下 TCP + 445 的 IP 包,修改其中 TCP 端口后无脑转发的;结果发现 Windows 禁止了 TCP 的 RawSocket。后续查了查 WinPcap 似乎可以拿来直接往网卡里塞链路层数据包,感觉做起来就麻烦了==
继续回到刚刚的话题,我们关掉了 Windows 自带的文件共享服务,netstat -an | find ":445" 已经没有结果了。然后我们只需要将远程的某个非 445 端口转发至本机 127.0.0.1 或者其他 IP (这里我直接添加了一张虚拟Loopback网卡并手动设置IP)即可。经尝试 netsh 自带的端口转发贼蠢。考虑到域名解析的问题,干脆直接写个转发程序好了。
有兴趣的可以 clone 下来本文最上方的 repo 自己 build 一下。
PS:推荐使用 nssm 注册系统服务来自动启动。
UPDATE(9/21/2019): Windows 大版本升一下就重新搞开了 445 ,关起来一次比一次费劲。弃了弃了,转投 RaiDrive 走 WebDAV了。
Aria2 + WebUI + Caddy
作为NAS必备功能就是下载。这里直接使用Aria2。由于懒得做权限控制,直接跑Docker了。
Dockerfile (build完19.7M):
1 | FROM alpine:edge |
docker-compose.yml:
1 | version: '2' |
aria2.conf:
1 | save-session=/aria2-data/aria2.session |
Caddyfile:
1 | https://sub.ihc.im { |
启用基于 DNS(CF) 的 ACME 需要配置环境变量 CLOUDFLARE_EMAIL, CLOUDFLARE_API_KEY。
为啥非要基于DNS呢?还不是因为小米路由器垃圾,映射不了80!
(不过运营商没有封80,443也很奇怪)
/var/www:
1 | git clone https://github.com/ziahamza/webui-aria2.git |
当然,对于 BT 下载来说连不上 Tracker 是常有的事,DHT 冷启动比较慢,可以从别处 Copy 一份 dht.dat 来避免冷启动。
以及,BT 下载涉及到端口穿透的问题。若有公网 IP 并且配置了端口穿法或 UPNP,那么可以被所有 seeder 连接;但如果没有公网可达的方式,就只能主动连接到有公网 IP 的 seeder 了。我们如果正确配置了公网穿透,下载速度会有大幅提升。可以手动添加 listen-port=11111 至 aria2.conf ,然后通过 docker 转发该端口,或者以 host 模式配置网络;并在路由器上启用 UPNP 或手动配置映射。
由于开启 UPNP 可能会导致局域网内其他机器成为百度云减速之类软件的 P2P 节点占用上传带宽,我直接配置了固定的端口及其公网映射,并关闭路由器的 UPNP 。
几年前搞过一个自动下载迅雷播放器字幕的工具,当时的实现是使用 inotify 直接监控 *.aria2 文件的删除操作,该任务文件被删除则认为下载完成,然后计算视频 Hash 后请求迅雷服务器,下载对应字幕。可是对于映射进 docker 容器的 volume , inotify 并不 work。于是要么用该方法在本机搭建,但是感觉很不优雅。
查 aria2 的文档发现有 完成通知 功能,于是又搞了一个 docker 分支拿来实现一个支持字幕自动下载的 aria2。自动下载脚本基本是不需要改变的,干脆直接 build 进 image。
1 | #! -*- coding:utf-8 -*- |
脚本获取命令行传入的任务 GID,之后通过 RPC 拿到这个任务对应的所有文件的路径,传入 SubtitleDownloader 下载。
其实这里会有一个问题,就是当容器开机自动运行时,可能这时 Ceph RBD 还没有挂载上。解决方案也很简单,定义一下启动顺序即可。systemctl list-units 后找到对应的 .mount ,然后直接在 /etc/systemd/system/multi-user.target.wants/docker.service 的 After 和 Requires 中添加该 .mount。
UPDATE-2019-05-25:
在下载器下载大流量数据后,机器会进入无响应状态。可能是kernel的bug,有人将docker容器通过特权模式启动避免该问题,这里我试着将本容器以host的方式启动以避免对大流量的转发。
May 24 16:27:42 x kernel: [433867.229731] br-d80dbce22414: port 1(vethc844fd0) entered disabled state
May 24 16:27:42 x kernel: [433867.229883] veth34c9ec0: renamed from eth0
May 24 16:27:42 x kernel: [433867.280301] br-d80dbce22414: port 1(vethc844fd0) entered disabled state
May 24 16:27:42 x kernel: [433867.283093] device vethc844fd0 left promiscuous mode
May 24 16:27:42 x kernel: [433867.283098] br-d80dbce22414: port 1(vethc844fd0) entered disabled state
May 24 16:27:48 x kernel: [433873.100394] IPv6: ADDRCONF(NETDEV_UP): br-382844c413a5: link is not ready
May 24 16:27:50 x kernel: [433874.880768] br-382844c413a5: port 1(veth2a40bca) entered blocking state
May 24 16:27:50 x kernel: [433874.880773] br-382844c413a5: port 1(veth2a40bca) entered disabled state
May 24 16:27:50 x kernel: [433874.880902] device veth2a40bca entered promiscuous mode
May 24 16:27:50 x kernel: [433874.881188] IPv6: ADDRCONF(NETDEV_UP): veth2a40bca: link is not ready
May 24 16:27:51 x kernel: [433876.156838] eth0: renamed from veth6d6a1df
May 24 16:27:51 x kernel: [433876.180811] IPv6: ADDRCONF(NETDEV_CHANGE): veth2a40bca: link becomes ready
May 24 16:27:51 x kernel: [433876.180905] br-382844c413a5: port 1(veth2a40bca) entered blocking state
May 24 16:27:51 x kernel: [433876.180910] br-382844c413a5: port 1(veth2a40bca) entered forwarding state
May 24 16:27:51 x kernel: [433876.180983] IPv6: ADDRCONF(NETDEV_CHANGE): br-382844c413a5: link becomes ready
May 25 00:01:36 x kernel: [461110.962617] libceph: mon0 192.168.31.18:6789 session lost, hunting for new mon
May 25 00:03:26 x kernel: [ 0.000000] Linux version 4.19.0-0.bpo.4-amd64 (debian-kernel@lists.debian.org) (gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1)) #1 SMP Debian 4.19.28-2~bpo9+1 (2019-03-27)
May 25 00:03:26 x kernel: [ 0.000000] Command line: BOOT_IMAGE=/boot/vmlinuz-4.19.0-0.bpo.4-amd64 root=UUID=2c6fd6e7-2f7a-4535-9904-753584e76e9b ro quiet
May 25 00:03:26 x kernel: [ 0.000000] x86/fpu: x87 FPU will use FXSAVE
May 25 00:03:26 x kernel: [ 0.000000] BIOS-provided physical RAM map:
May 25 00:03:26 x kernel: [ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000003efff] usable
May 25 00:03:26 x kernel: [ 0.000000] BIOS-e820: [mem 0x000000000003f000-0x000000000003ffff] ACPI NVS
UPDATE-2019-05-25:
Kernel 没有问题,是小米路由器太垃圾,经常断流导致。断流表现是通过有线或无线的形式连接着路由器,连接显示没有问题,但是根本不通。这种情况频率几乎一天一次,流量大的时候一天三次的情况也有。
已退货。
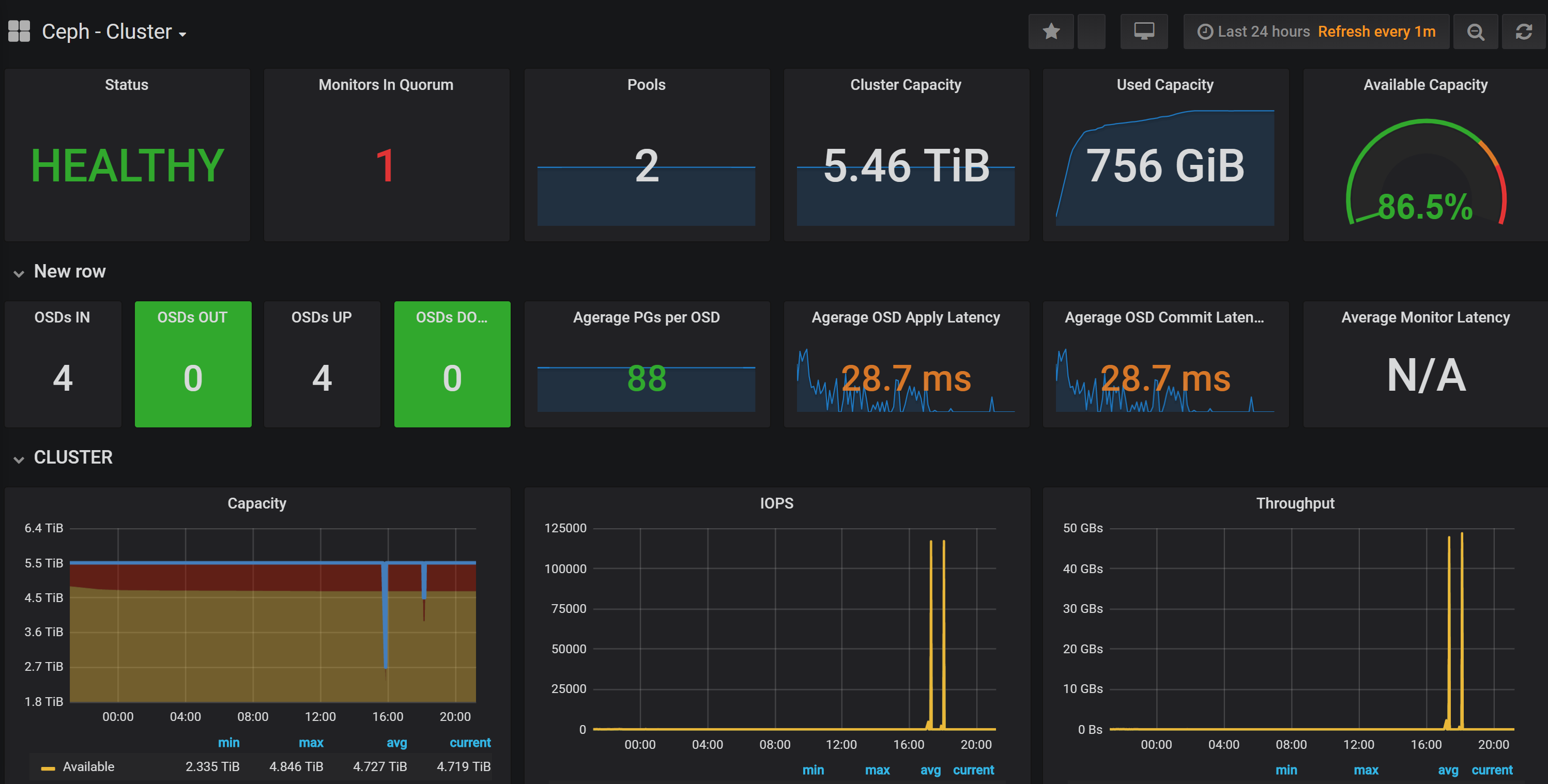
Ceph_exporter + Prometheus + Grafana
集群(虽然我是单机)监控也是很重要的,毕竟硬盘坏了就炸了。及时更换硬盘可以保证重要文件不会丢失。
ceph-exporter 用于提供采集 ceph 集群数据接口,prometheus 用于采集和存储数据,grafana 用于可视化数据。
继续偷懒,直接跑官方的 docker 镜像。这里为了尽可能少地暴露端口,直接使用 docker-compose 将不同的 container 连接起来。
docker-compose.yml:
1 | version: '2' |
创建 grafana-data 与 prometheus-data 并给与任意用户的写权限,用来持久化采集的数据和 grafana 配置;在 prometheus.yml 的末尾添加:
1 | - job_name: 'ceph_exporter' |
在配置 grafana 时,数据源主机名写 prometheus 即可。
DNS + VPN + MTProxy
顺手搭点小玩意。
DNS 使用 overture 替代之前常用的 ChinaDNS;VPN 使用 ShadowVPN,并在启动后自动添加 Telegram IP 段的路由;MTProxy 提供外网移动设备使用。
之前尝试了使用 V2ray 来中转 MTProxy,即在 NAS 上跑 MTP,然后 MTP 流量走 Shadowsocks 出去,但是初次连接时间较长,Telegram 一直显示 Connecting。后来改了下代码,加了一个预先建立的连接池试图减少初次的连接时间(CODE),但是即便如此时间也是蛮久的,要好几秒钟,感觉不是我这边的问题。
既然建立了 VPN 连接,那么将 TG IP 段路由做好,那直接在本地跑官方版本 MTP 应该也是 work 的,然而似乎这个东西还依赖了其他被墙资源,本地启动失败。看了下启动文件,似乎是获取了两个 core.telegram.org 的文件,并且 DNS 自动用了系统的,也就是另一个容器提供的,而错误就是域名解析失败。
我感觉这是一个 bug,就是当容器连接主机端口时应当是可以连接的;但是如果这个端口是某个容器的映射端口,那么可能docker0就直接处理掉了,而在处理这个逻辑的时候碰到了namespace隔离。于是表现就是这个容器并不能连接另一个容器映射至宿主机的 53 端口。我在 caddy 里做了一个反向代理避开了这个问题。在本地跑起来官方版本的 MTProxy 后,iOS Telegram 刚启动的时候依然要 Connecting 非常久。这就非常奇怪了。
嗯,最后发现是 iOS Telegram 的问题。升到 Testflight 的测试版本后问题消失。
是真的坑。
UPDATE(9/21/2019):
DNS 更换为 Unbound,VPN 更换为 TincVPN,MTProxy处于半弃用状态。
Unbound
在 Unbound 的配置中使用了一些已有的名单来做分流,国内域名直接使用国内上游 DNS 解析,可以提升解析和访问速度;国外域名使用经 VPN 路由的国外上游 DNS,保证结果无污染。
另一个问题是 ipv6。本地有 ipv6,但是 VPN 没有 ipv6 出口,所以用了丑一点的方式,对某些支持 ipv6 的大站点做了手动覆盖。比如 google 直接解析至单一固定 ipv4 地址,这样一定程度上也能起到加速作用。
TincVPN
VPN 换成了 TincVPN。TincVPN 的好处是可以做到高可用,并且可以同时接入多个内网。经测试上海联通可能要开 TCPOnly,不开的话大流量一段时间后 udp 会慢成傻狗。
有了 VPN 我们还需要分流。
这里我用了 apnic 和 17mon 的 geoip 数据,拿到国内 IP 段后创建 ipset。之后创建一张新的路由表,默认走我们的 Tinc 的 interface (节点之间怎么路由是 Tinc 的事情,我们不管)。然后创建 iptables mangle 表里创建一条新的链:对于国内 IP 或者我们不想让其走代理的 IP (如 Tinc 的国外节点),我们直接放行;否则打标记。而我们已经设置了 IP rule,对于有标记的连接使用我们创建的这张路由表,所以所有不在名单里的 IP 段都会走 Tinc 。最后在 nat 表里记得开启 MASQUERADE。
注意我们这里只对 mangle 表做了处理,对于本机的流量我们是不会动的。这样可以避免大流量下载占用 VPN 带宽或 VPS 吃 TOS。
对于内网主机,我们可以直接将网关指向本服务器。我们同时也在内网起了一个 shadowsocks 服务端,并端口映射至公网。通过指定该 shadowsocks 服务容器的 ip,我们可以让其流量接受透明代理的管理。
MTProxy
这东西很废。启动时需要向 Telegram 远程的服务器设置出口 IP,而对于我们的 Tinc,是不容易确定出口 IP 的。还是走 shadowsocks 吧。
总结
系统基于 Ceph 实现了支持多副本和动态扩容及容错的存储、基于 Aria2 和 Aria2-WebUI 的下载器和视频字幕自动下载、基于 Prometheus 和 Grafana 的 Ceph 状态监控和基于 Samba 的远程文件系统挂载支持,最后通过 Caddy 反代至统一的出口。
除网络代理, Ceph , Samba 和 Caddy 外所有服务均使用 docker 和 docker-compose 部署。
(Unbound、TincVPN 也直接部署本机了23333)
项目开源于 Github: https://github.com/ihciah/NAS-tools/